XML文件的Dom解析和SAX解析
1、XML简介
xml是一种通用的数据交换格式,由于他的平台无关性,语言无关系,系统无关系给数据的集成和交换带来了很大的便利。xml在不同的系统中解析方式一样,只是使用的语言不一样而已。
通常的解析方法有:DOM,SAX,JDOM,DOM4J。前两种方法是基础方法,后两种方法是在基础方法上进行扩展,只适用于java。下面只介绍DOM,SAX两种方法。xml文件例子如下:
<?xml version="1.0" encoding="UTF-8"?>
<persons>
<book id="1">
<name>Thinking in JAVA</name>
</book>
<book id="2">
<name>Core JAVA2</name>
</book>
<book id="3">
<name>C++ primer</name>
</book>
</persons>
2、DOM解析
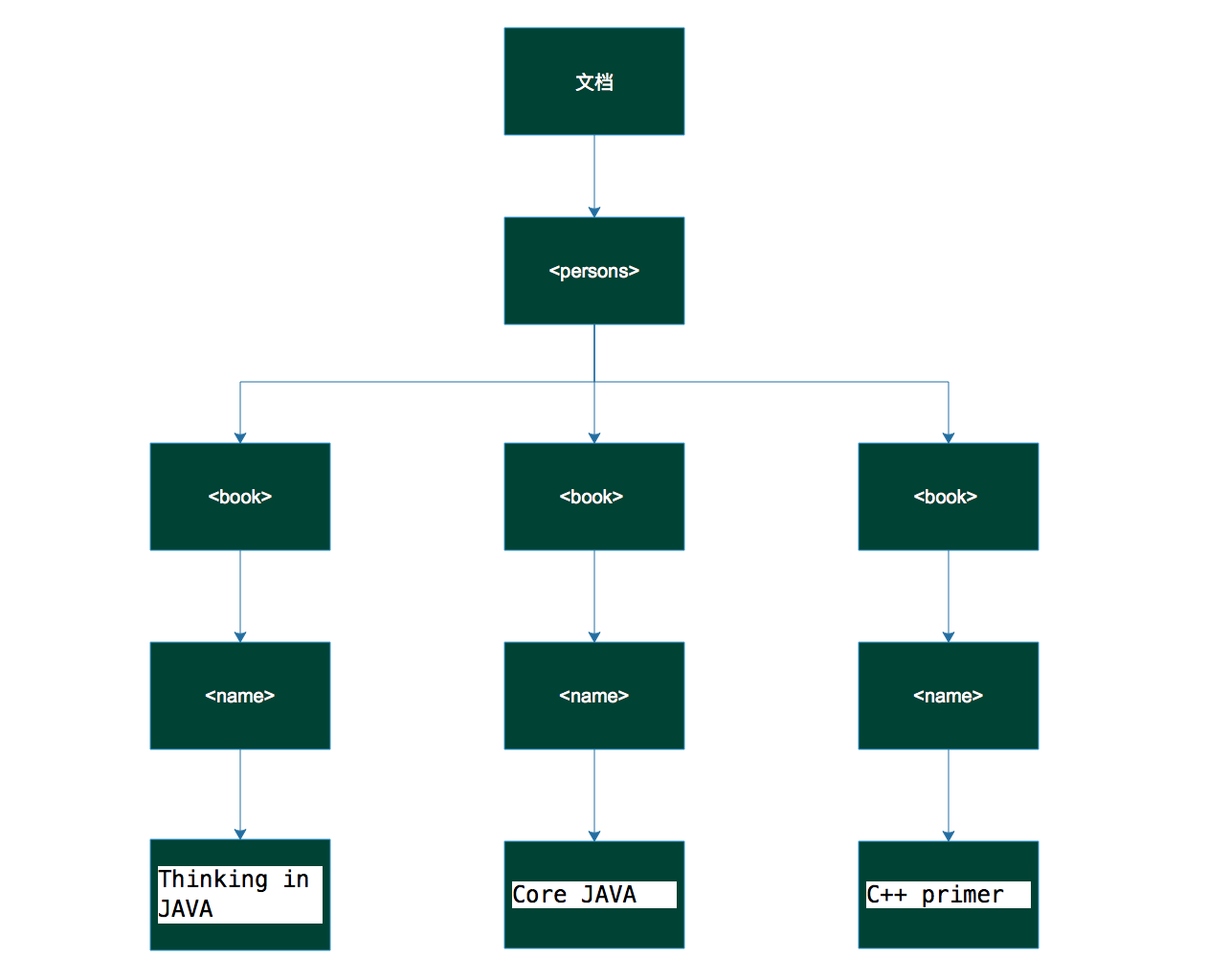
DOM是文档对象模型,依据其标准xml中的所有内容都是节点:
- 整片文档都是一个节点;
- 每个元素是一个元素节点;
- 每个文本都是一个文本节点;
- 注释是注释节点;
- 属性是属性节点;
上述XML文档可建立DOM节点树如下图:
常用方法:
一些常用的 HTML DOM 方法:
• getElementById(id) - 获取带有指定 id 的节点(元素)
• appendChild(node) - 插入新的子节点(元素)
• removeChild(node) - 删除子节点(元素)
一些常用的 HTML DOM 属性:
• innerHTML - 节点(元素)的文本值
• parentNode - 节点(元素)的父节点
• childNodes - 节点(元素)的子节点
• attributes - 节点(元素)的属性节点
nodeValue 属性规定节点的值:
• 元素节点的 nodeValue 是 undefined 或 null
• 文本节点的 nodeValue 是文本本身
• 属性节点的 nodeValue 是属性值
访问元素的常用方法:
• 通过使用 getElementById() 方法
• 通过使用 getElementsByTagName() 方法
• 通过使用 getElementsByClassName() 方法
解析的优点:
1、形成了树结构,有助于更好的理解、掌握,且代码容易编写。
2、解析过程中,树结构保存在内存中,方便修改。
DOM解析的缺点:
1、由于文件是一次性读取,所以对内存的耗费比较大。
2、如果XML文件比较大,容易影响解析性能且可能会造成内存溢出。
下面是一个对上面xml文档的一个解析demo:
import org.w3c.dom.Document;
import org.w3c.dom.Node;
import org.w3c.dom.NodeList;
import javax.xml.parsers.DocumentBuilder;
import javax.xml.parsers.DocumentBuilderFactory;
import java.io.File;
public class DOMParsingOfXml {
public static void main(String[] args) throws Exception {
// 静态创建DOM文件构建工厂
DocumentBuilderFactory documentBuilderFactory = DocumentBuilderFactory.newInstance();
// 创建Dom文件构造器
DocumentBuilder documentBuilder = documentBuilderFactory.newDocumentBuilder();
File file = new File("/Users/XXXX/workspace/zy-test/src/main/resources/xmlParsing.xml");
// 解析文件得到dom类
Document document = documentBuilder.parse(file);
// 依据标签名获得该名称的所有节点
NodeList bookList = document.getElementsByTagName("book");
for(int i = 0; i < bookList.getLength(); i++) {
Node book = bookList.item(i);
// 获得该节点的所有子节点
NodeList nameList = book.getChildNodes();
// 遍历所有节点
for(int j = 0; j < nameList.getLength(); j++) {
Node name = nameList.item(j);
// 方法二:判读子节点为元素节点,并且节点名称为name,则输出其第一个子节点内容
if (name.getNodeType() == Node.ELEMENT_NODE && name.getNodeName().equals("name")) {
System.out.println(name.getFirstChild().getNodeValue());
}
// 方法二:判读改节点是否还有子节点,没有表示页子节点,则输出节点内容;
if (name.hasChildNodes()) {
System.out.println(name.getFirstChild().getNodeValue());
}
}
}
}
}
SAX解析
SAX简称simple APIs for Xml,及xml文档简单应用接口。SAX提供的是一种顺序访问模式,一种快速读取xml数据的方法。
当SAX解析xml文档的时候会触发一系列的事件,调用一系列的事件处理方法。应用程序就是通过事件处理方法来访问xml的数据,
因此,sax又叫一种事件驱动接口;sax解析一般需要基础defaultHandle方法,重写事件处理方法。
sax优点:
1、采用事件驱动模式,对内存耗费比较小。
2、适用于只处理XML文件中的数据时。
缺点:
1、编码比较麻烦。
2、很难同时访问XML文件中的多处不同数据。
sax解析一般需要基础defaultHandle方法,重写事件处理方法。
import org.xml.sax.Attributes;
import org.xml.sax.SAXException;
import org.xml.sax.helpers.DefaultHandler;
public class SAXHandle extends DefaultHandler{
public String preNode;
/**
* 解析文档开始调用方法
* @throws SAXException
*/
@Override
public void startDocument() throws SAXException {
System.out.println("-------startDocument------");
}
/**
* 解析文档结束调用方法
*/
@Override
public void endDocument() throws SAXException {
System.out.println("-------endDocument------");
}
/**
* 解析元素开始调用方法
*/
@Override
public void startElement(String uri, String localName, String qName, Attributes attributes) throws SAXException {
preNode=qName;
}
/**
* 解析元素结束调用方法
*/
@Override
public void endElement(String uri, String localName, String qName) throws SAXException {
preNode=null;
}
/**
*解析文本元素调用方法
*/
@Override
public void characters(char[] ch, int start, int length) throws SAXException {
if (preNode != null && preNode.equals("name")) {
System.out.println(new String(ch,start,length));
}
}
}
import javax.xml.parsers.SAXParser;
import javax.xml.parsers.SAXParserFactory;
import java.io.File;
public class SAXParsingOfXml {
public static void main(String[] args) throws Exception {
// 创建SAX解析工厂
SAXParserFactory saxParserFactory=SAXParserFactory.newInstance();
// 创建SAX解析
SAXParser saxParser=saxParserFactory.newSAXParser();
File file = new File("/Users/XXXX/workspace/zy-test/src/main/resources/xmlParsing.xml");
// 解析文档
saxParser.parse(file,new SAXHandle());
}
}
参考文档
http://www.w3school.com.cn/htmldom/dom_nodes.asp
http://www.cnblogs.com/longqingyang/p/5577937.html

